mario.recalde@conversacion.digital
"Aplicación inteligente para profesionales del Derecho: consulta de documentos sin leer"
Aprovechando los modelos LLM para conversar con nuestra propia información
Introducción:
Participar en el programa de tutoría de KaggleX fue una experiencia esclarecedora y enriquecedora. Fue una gran oportunidad para desarrollar un proyecto bajo la guía de un profesional experimentado, como mentor (en mi caso Henry Ruiz PhD ) y la ayuda de todo el increíble equipo de KaggleX.
Al comienzo de este viaje, hace casi dos meses, estaba decidiendo entre desarrollar un proyecto basado en pronóstico de series temporales o un proyecto basado en procesamiento de lenguaje natural. Ambos temas eran algo en lo que quería mejorar mi comprensión.
Después de la evaluación inicial decidí optar por la segunda opción y desarrollar una solución que pudiera ser útil tanto para particulares como para empresas y, por qué no, poder comercializar. Decidí centrarme en una aplicación para la industria jurídica o la práctica de abogados y notarios. Incluso escribí un párrafo de venta:
“En el panorama en constante evolución de la documentación legal, ha surgido una solución innovadora que promete revolucionar la forma en que los profesionales del derecho interactúan con documentos extensos. Este artículo profundiza en la innovadora "Aplicación inteligente para profesionales jurídicos", una aplicación de vanguardia basada en modelos de lenguaje grandes (LLM) y procesamiento del lenguaje natural (NLP). ¿Su misión? Permitir que abogados, notarios y otros expertos legales consulten y extraigan información vital de documentos complejos sin la necesidad de una lectura extensa. Esta es una solución transformadora que tiene el potencial de redefinir la eficiencia en la industria legal”.
A lo largo de este viaje, describiré la evolución del proyecto, los desafíos encontrados y los diversos caminos recorridos, hasta llegar a una aplicación final, que probablemente no se pueda describir con el párrafo anterior, pero es un primer paso en esa dirección.
Definición del proyecto
Explorar el potencial de LLM (Large Language Models) y NLP (Natural Language Processing) para fine-tuning y prompting engineering para "conversar" con documentos electrónicos, extraer información valiosa y mejorar la eficiencia de los profesionales del derecho.
Los conceptos clave cubiertos en este proyecto fueron:
- IA generativa para texto.
- Procesamiento del lenguaje natural (NLP).
- Modelos de lenguaje extensos (LLM).
¿Qué aprendí?
Este proyecto ha sido un viaje revelador y he adquirido conocimientos valiosos en varias áreas:
1. Diferentes tipos de LLM:
Aprendí sobre los distintos modelos de lenguajes extensos (LLM) disponibles para diferentes aplicaciones.
2. Ajuste fino:
Profundicé en las complejidades de ajustar un modelo de lenguaje (fine-tuning) y entendí la importancia de utilizar datos específicos a la tarea para la que se quiere mejorar su rendimiento.
3. Ingeniería de indicaciones:
Exploré técnicas como Prompting Engineering y Retrieval Augmented Generation, que tienen el potencial de optimizar la interacción entre usuarios y documentos.
Empoderar a los profesionales jurídicos
El objetivo principal de este proyecto fue desarrollar una aplicación que satisfaga las necesidades de los profesionales del derecho, incluidos abogados y notarios. Estos profesionales a menudo necesitan revisar documentos extensos, un proceso que consume mucho tiempo y es costoso. Sin embargo, nuestra aplicación pretende cambiar eso al permitir a los usuarios hacer preguntas específicas sobre un documento sin la necesidad de leerlo en su totalidad. Esta solución innovadora puede ahorrar tiempo y recursos valiosos.
El estado del arte del LLM en palabras simples
El campo de las aplicaciones desarrolladas utilizando modelos de lenguaje extensos está en continua evolución. Mantenerse al día con el ritmo de los avances puede ser un desafío para un individuo. El panorama está inundado de nuevas bibliotecas, aplicaciones y métodos. Este proyecto sirvió como una oportunidad para explorar las fronteras de este campo.
Evolución de LLM (Transformadores)
La evolución de los LLM es notable. Desde el entrenamiento previo de modelos desde cero con pesos aleatorios hasta el ajuste con datos de tareas específicas, el progreso en esta área es notable.
 Ref. HuggingFace")
La idea original
El proyecto comenzó con la idea de entrenar un modelo LLM Open Source con documentación legal específica, como la del sitio web de SINARDAP. El objetivo era aprovechar este modelo para crear una aplicación que extrajera información de documentos similares. Sin embargo, este objetivo presentó su propio conjunto de desafíos.

¿Cómo empezó?
Mi viaje comenzó aprendiendo la terminología y los conceptos de IA generativa, particularmente referentes a PNL y LLM. El
curso de
PNL de HuggingFace fue un recurso valioso que proporcionó conocimientos e ideas para su implementación. Adquirí un conocimiento profundo de los LLM, los transformadores y el proceso de ajuste (fine-tuning). Extraer información de los
archivos PDF de SINARDAP y formatearla para realizar ajustes fue una parte importante de la fase inicial.

Código para extraer datos
Desarrollé código para extraer datos de archivos PDF, que está disponible en [GitHub] ( https://github.com/mhrecaldeb/KaggleXMentoringProgram ). Los archivos dentro de este repositorio lograron una variedad de objetivos, desde web scraping hasta descargar archivos PDF, extraer texto de archivos PDF y concatenar todo el texto de una manera que pudiera usarse para ajustar un modelo. Debido al nivel de variabilidad de formatos en los sitios web y en los archivos PDF, la extracción de información resultó ser una tarea enorme. Además, el ajuste del uso de las bibliotecas de HuggingFace presentó sus propios grandes desafíos y el nivel de recursos necesarios superó los que tenía disponibles.

Después de algunas semanas luchando con las bibliotecas de HuggingFace, decidí probar algunas opciones low-code y aprovechar el cupón que KaggleX entregó a los aprendices al comienzo del programa como parte de las herramientas que podíamos usar para desarrollar los proyectos.
La experiencia con Google Cloud
Explorar Google Cloud ofreció herramientas prometedoras como Vertex AI para ajustar los modelos de lenguaje. Sin embargo, la tarea resultó ser compleja y requería muchos recursos. A pesar de los intentos de conseguir recursos computacionales adicionales, fue un desafío avanzar con este enfoque.
Vertex IA:
Ofreció una plataforma para ajustar modelos de lenguaje con un archivo JSON generado en la primera etapa del proyecto. Sin embargo, incurrió en costos elevados y el cupón entregado por el programa KaggleX se consumió y, finalmente, esta opción no logró brindar los resultados deseados.
")
Search & Chat:
En Generative App Creator de Google Cloud se permitía la creación de aplicaciones de búsqueda y chat utilizando modelos predefinidos. A pesar de que este tipo de solución era muy fácil de crear y tenía opciones para implementar interfaces UI para permitir a los usuarios aprovecharlas, los resultados durante las pruebas a menudo eran inexactos.


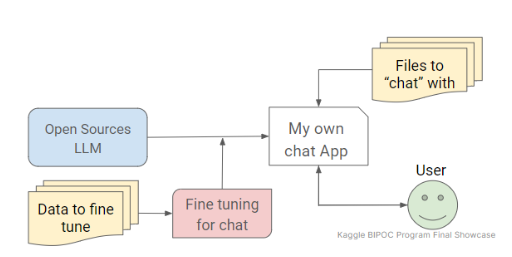
¿Cómo terminó? - LangChain
Teniendo en cuenta las limitaciones de tiempo y recursos, encontré una solución alternativa utilizando las bibliotecas OpenAI y LangChain . Este enfoque me permitió utilizar Prompting Engineering y Retrieval Augmented Generation. En términos de complejidad, esta solución estaba a medio camino entre las otras dos. Y tenía el potencial para implementar lo que era el objetivo principal de este proyecto.
Codificación usando LangChain
LangChain se utilizó para todo, desde llamar a un modelo OpenAI, cargar archivos PDF, dividir la información, crear una base de datos vectorizada, generar embeddings y establecer una cadena RetrievalQA.
Para poder comprender y desarrollar mi propia solución, completé los siguientes cursos de Deeplearning.IA :
- LangChain for LLM Application Development.
- LangChain: Chat with Your Data.
El código para conversar con tus datos está disponible en: [GitHub]( https://github.com/mhrecaldeb/chat-with-your-data ).
Experimenté con varios tipos de métodos en cada parte del código, por ejemplo, para la base de datos vectorizada comencé a probar Chroma para una base de datos en disco (persistente) pero finalmente nos conformamos con FAISS (Meta) para una base de datos en memoria.
UI (Streamlit)
Desarrollé una interfaz de usuario usando Streamlit , lo que facilitó la interacción con la aplicación. Sin embargo, hubo desafíos al cargar archivos PDF, lo que llevó a ajustes en el enfoque.
- Necesitaba cambiar el método para dividir la información extraída de los archivos PDF ya que el método de carga de PDF LangChain no funcionaba para cargar documentos usando un botón en Streamlite, y mucho menos varios documentos.
- Este cambio en el método de carga de PDF afectó el código tanto en el objeto que se utiliza para dividir el texto, y a partir de ese momento la estrategia fue trabajar con texto plano en lugar de con documentos.
- En lugar de usar “RecursiveCharacterTextSplitter”, tuve que usar “CharacterTextSplitter”, en consecuencia necesitaba usar “text_splitter.split_text”, en lugar de “text_splitter.split_documents”, así como “FAISS.from_texts” en lugar de “FAISS.from_documents” .

El enlace para acceder a la aplicación es: https://smartapp-dontread-yourdocs.streamlit.app/


En conclusión
Este proyecto ha sido un viaje de exploración, aprendizaje y adaptación. Si bien enfrentó desafíos en el camino, finalmente condujo a una solución que permite a los profesionales legales extraer información de manera eficiente. El campo de los modelos de lenguajes grandes continúa evolucionando y sigo entusiasmado con las posibilidades que ofrece para el futuro.
Quién sabe, tal vez en el futuro pueda realizar ajustes finos en un LLM y usar otros modelos como Llama 2 para herramientas similares a esta pero más precisas.




